
Parcels documentation#
Welcome to the documentation of Parcels. Parcels (Probably A Really Computationally Efficient Lagrangian Simulator) is a set of Python classes and methods to create customisable particle tracking simulations using output from Ocean Circulation models. Parcels can be used to track passive and active particulates such as water, plankton, plastic and fish.
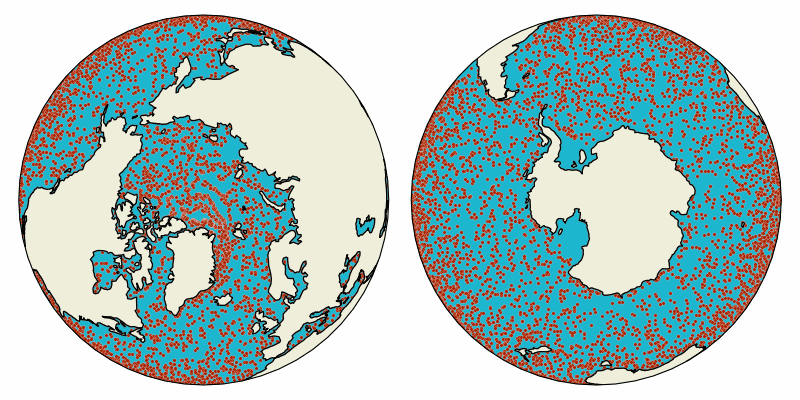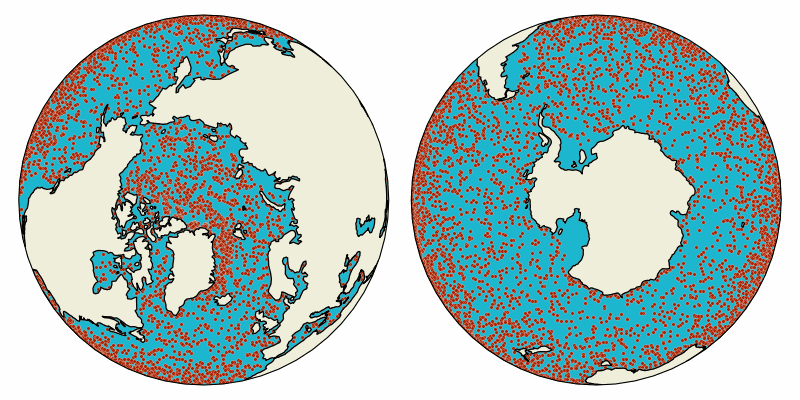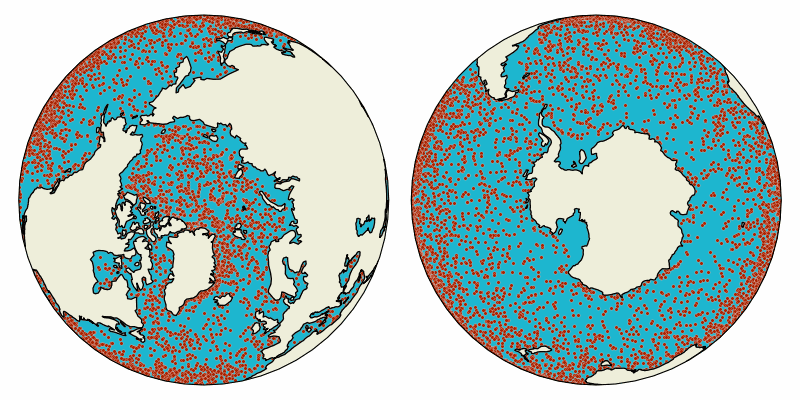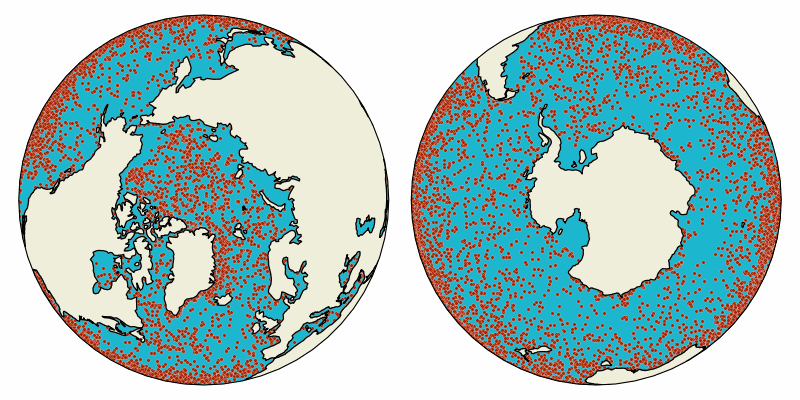
Animation of virtual particles carried by ocean surface flow in the global oceans. The particles are advected with Parcels in data from the NEMO Ocean Model.
Here you’ll find installation instructions, tutorials and documentation, and the API reference for Parcels. You can browse the documentation for older versions by using the version switcher in the left sidebar.
If you need more help with Parcels, try the Discussions page on GitHub. If you think you found a bug, file an Issue on GitHub. If you want to help improve Parcels, see the Contributing page.